これは何?
2020年の年始、こんなツイートをした
バイナリであけおめ!皆様今年もよろしくお願いします! pic.twitter.com/v9UfgCNzB1
— Naoya✌️😐 (@nakir323) 2020年1月2日
この中で実行可能なファイルをバイナリエディタで開いて「2019」を「2020」に書き換えた。このとき、2019は「32 30 31 39」と書かれていたのだが、UTF-8の文字コード表を見て、なるほど😁なったのも束の間、シフトJISの文字コード表を見ても同じ文字コードが書かれていてどっちやねん!?ってなった。これがこの記事の発端です。
UTF-8とかShift_JISとかUnicodeとかって何で、言葉の次元としてはどういう関係なのか?バイナリにはなぜ「32 30 31 39」と書かれていたのか?ソースコードのファイルのエンコードとは?このあたりをきっちり理解したいです。
言葉の定義を理解する
文字集合
(英:character set) 文字を要素とする集合のこと。例えば、アルファベットは「A~Z」を要素とする文字集合であるし、「あ〜ん」もひらがなの文字集合と言える
符号
一般には記号・しるしという意味。数学では特に+/-のこと(常に+/-を指す言葉だと思ってた!)
符号化文字集合
(英:coded character set) 印がつけられた文字集合のこと。つまり、文字集合の中の各々の文字を一意に特定できる記号(符号化表現)がつけられた文字集合のこと。 JIS X 0201、JIS X 0208、ISO/IEC 10646などがある。例えば、数字の「1」は31、「A」は41など(JIS X 0201の例)。このときの31や41といった符号をコードポイントと呼ぶ。
- JIS X 0201 : 英数字やカタカナの規格
- JIS X 0208 : 漢字、非漢字など約7000文字の規格
- ISO/IEC 10646 : 約6万文字の漢字の規格
- ASCII, Unicodeも符号化文字集合のうちの1つ
文字符号化方式
(英:character encoding scheme) ASCIIは単体で運用されることが多いが、他の符号化文字集合ではいくつかの符号化文字集合を組み合わせて利用したい場合がある。そこで、そういった複数の符号化文字集合を組み合わせて運用する方式を文字符号化方式と呼ぶ。
文字符号化方式にはShift_JISやUTF-8などがある。Shift_JISはJIS X 0201とJIS X 0208を組み合わせたもの。また、UTF-8はISO/IEC 10646とUnicodeで使える文字を収録している。
ポイントとしては、同じ文字を表していたとしても、符号化文字集合のコードポイントと文字符号化方式の符号(文字コード)は違う場合があるということ。例えば、Unicodeにおいて「あ」はU+3042と表し、UTF-8では16進数でE38182と表す。(つまり0xE38182。[0x]は後に続く文字が16進数であることを示す。)
文字符号化方式はコンピュータで利用する前提でコードが決められているが、符号化文字集合はそうとも限らないということもあり、こういった違いが発生する。
文字コード
文字をコンピュータで扱うためのバイト表現のこと。または、その文字とバイト表現の対応関係。 符号化文字集合はバイト表現であるとは限らないが、符号化文字集合と文字符号化方式をまとめて文字コードと表現することもある。
エンコード
=符号化。あるデジタルデータを一定の規則に従って符号に変換すること。
例文:「あ」をUTF-8でエンコードすると0xE38182になる。
文字コードを知る
ASCII
符号化文字集合の1つ。American Standard Code for Information Interchangeの略。
ラテン文字や数字などの英文でよく使われる文字を中心に、7ビットで表せる128種類の文字を収録している。
収録文字一覧を見てみると、基本的な文字、もう少し言えば基本的なプログラミング言語で必要な文字はだいたい網羅されてそう。
この時代から基本は1バイト単位でデータをやりとりしていたけど、なぜ7ビットかというと、1ビットはパリティビットに使っていたかららしい。パリティには奇数パリティと偶数パリティがあるが、例えば偶数パリティでは1バイトの中で1の個数が偶数になるように例えば一番左に1か0を追加する。もし文字コード部分が 0000001 だった場合、偶数パリティでは1の個数を偶数個(この場合は2個)にしたいので、先頭に1を足して 10000001とする
Unicode
符号化文字集合の1つ。
全世界の文字を1つの文字集合で扱うために開発された。これのPreface内Why Unicode?の箇所をみると、全ての文字が含まれた非常に膨大な、そしてプログラミングをする際に便利な文字コードを目指した旨が伝わってくる。
とにかくめちゃくちゃ量が多い。Unicodeの符号空間は16進数で 0 - 10FFFF である。つまり1,114,112符号位置が存在する。実際にはそのうち14万符号ほどに文字が割り当てられているみたい。
UTF-8
文字符号化方式の1つ。
基本的にはUnicodeに基づき1~4バイトで文字を表現する。ASCIIとの互換のため、ASCII文字は1バイトで表現している。
UTF-8では1~4の各バイトにルールがある。
- 1バイト文字→先頭ビットは
0 - 2バイト文字の1バイト目→先頭は
110 - 3バイト文字の1バイト目→先頭は
1110 - 4バイト文字の1バイト目→先頭は
11110 - 2~4バイト文字の2バイト目以降の各バイト→先頭は
10
このルールがあるおかげで、文字境界が確実に判別できる。例えば10001010だったら確実にある文字の2バイト目以降ということがわかる(先頭が10で始まってるから)。
ただあまりこの良さが分かってない😅どんなソフトウェアを作ればこの良さがわかるのかなぁ
プログラミングにおける文字コードの扱い
ここからはプログラミングをする上でどのように文字コードが扱われているかの話。基本的にはGo言語を使って説明します。が、知らない人にもわかるように書くつもりです。
ソースコードのファイルの文字コード
ソースコードの文字コードはどうなっているのかというと、GoにおいてはUTF-8で書くべきらしい。
Source code in Go is defined to be UTF-8 text; no other representation is allowed.
引用:Strings, bytes, runes and characters in Go - The Go Blog
ちなみにJavaだとJavaのソースコードのファイル形式は指定できるみたい🤔
https://qiita.com/seraphy@github/items/98e2908b63af58ef0032
ここで試しにソースコードをShift_JIS形式で作成し、go buildでビルドすると... なんとビルド成功、そして正しく実行できてしまった!
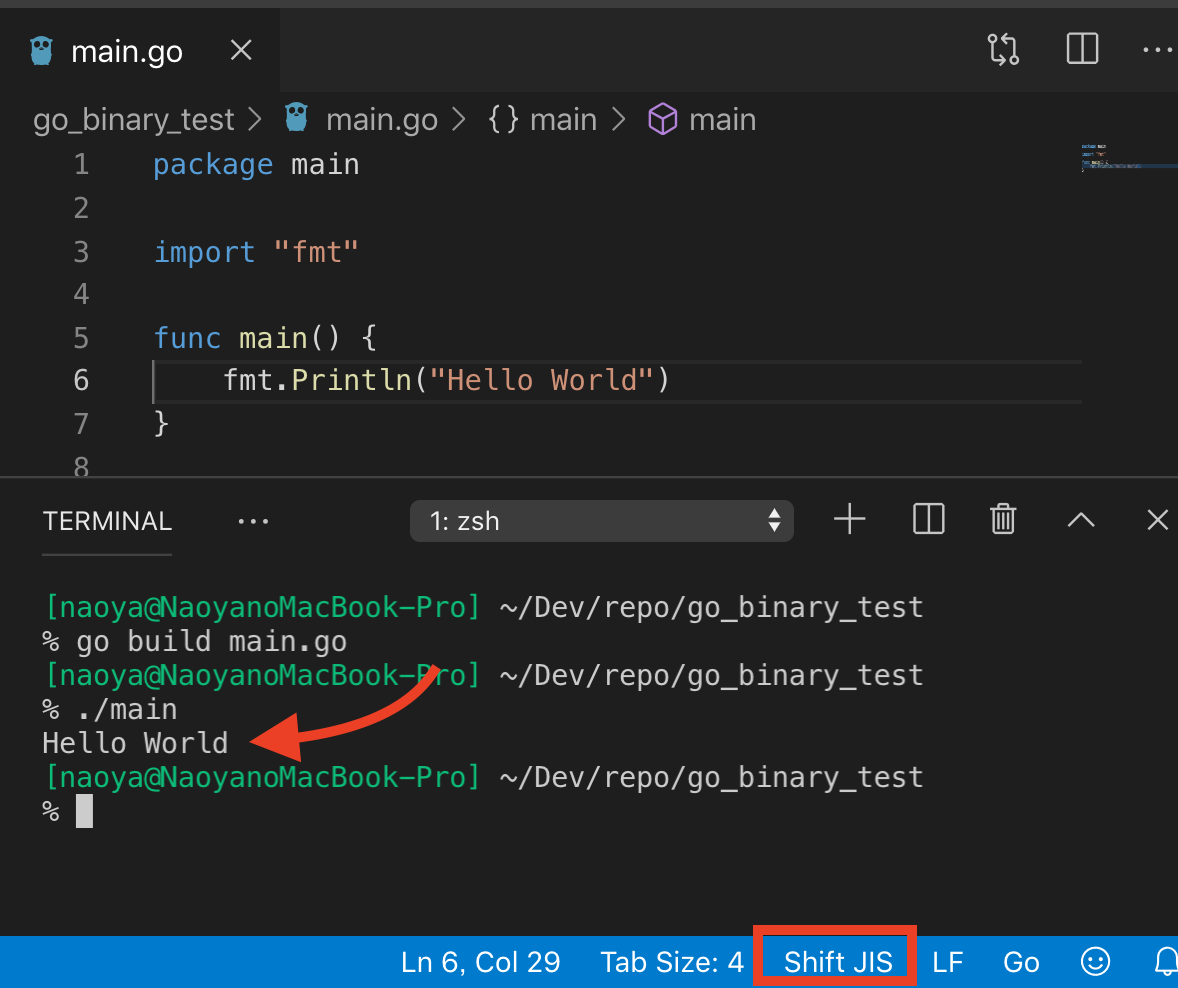
で、UTF-8とShift_JISの1バイト文字のコードを見てみると、0x7Fまでは同じ値になっているみたい。Goではファイルの文字コードはとりあえずUTF-8であるという前提で動作するようにできているみたい。
しかし、よく見るとShift_JISの1バイト文字はUTF-8と違う文字(半角カタカナ等)も定義されている。あれ、これってもしかして...
Shift_JISの「マ」と「コ」の文字コードはそれぞれ cf と ba。

そしてUTF-8の「Ϻ」の文字コードはCFBA

つまり、ソースコードをShift_JISにして 「マコ」を出力してみると...??
 きたー!!
きたー!!
なるほどね😊つまり、ファイルの文字コードがShift_JISの状態で「マコ」と入力して保存すると、ソースコードのファイルのバイナリではcfbaとして保存されている。そしてGoはコードをUTF-8として扱うようにできているので、それをUTF-8の文字として出力した。だから「Ϻ」って表示されたんですね。
最初の答え
自分がツイートした実行可能ファイルに2019が32 30 31 39と書かれていたのは、ソースコードをUTF-8で書いていたから、その文字コードがそのまま書かれていたことが理由に見えますね。(buildしたタイミングで自分が把握していない何かの処理がある可能性は捨てきれませんが)